When it comes to logging in cloud environments like OpenShift you often read about concepts only. Twelve-factor-applications, stateless containers, console or stdout logging. Everything nice. A point where the online sources get really spare is how to apply these concepts practically.
First things first, let’s do a short wrap up of the basic concepts and then about how to apply them practically in a cloud environment like OpenShift.
The twelve factor application (https://12factor.net) is a manifest that describes how to deliver software-as-a-service. The main concepts are
- Setup automation, to minimize time and costs
- Clean contracts with the underlying operating system to offer a maximum portability between execution environments
- Suitable for deployment on modern cloud platforms
- Minimize divergence between development and production, enabling continuous deployment
- Can scale up without significant changes to tooling
OpenShift in combination with Docker and stateless micro-services is a very good choice to achieve the goals proposed for the twelve factor app. With docker and kubernetes, we can automate the setup and also enable continuous deployment. When we run our software in docker containers, we get a maximum on portability because it is just a container we can shift from one system to another without worrying about the underlying operating system. The OpenShift scaling mechanism in combination with stateless microservices enables automatic scaling based on a load balancer.
Let’s now come to our main topic. The logs. The twelve-factor app manifest says that we should treat logs as event streams. This means we should not write to a log file as usual but write our messages simply to stdout. As this is the Docker default behavior, this fits pretty good to our tool-chain. With an external logging layer that handles all the processing and shipping of our log messages we separated by concerns and our applications and containers are not longer responsible for logging. Just send it out and let go.
How can we now implement this concept in reality? What problems will occur and have to be solved?
As already denoted, OpenShift with Docker is a really good candidate to deal with it. There exists already a predefined template for OpenShift to install Fluentd as a daemon set on all our nodes. FluentD will catch the docker container logs that are written to the directory /var/log/messages, grab them and send them out. If you want to know more about logging in OpenShift, visit https://docs.openshift.com/enterprise/3.1/install_config/aggregate_logging.html.
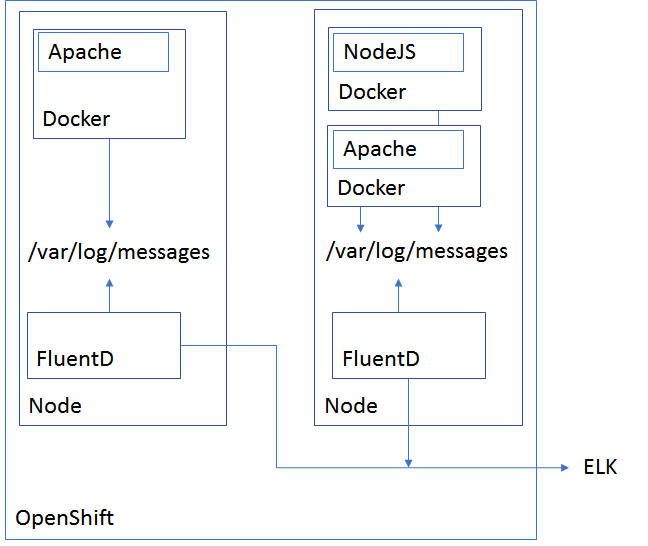
So what else has to be considered? What about our logging mechanism in our application container? What format should we use?
Let’s think about an Apache container as an example. Apache has basically two log files: The access and the error logs. In the time when we wrote our log messages to files, we knew whether log messages came from the error or the access log, because we knew the filename. Nowadays when we want to log everything to stdout, we need to apply this information to our log messages, to be able to apply our further processing rules later.
So what idea comes into my mind is to tag our messages and therefore know where they come from. For the Apache log this could look like this:
[Access] A log message from the access log
[Error] A log message from the error log
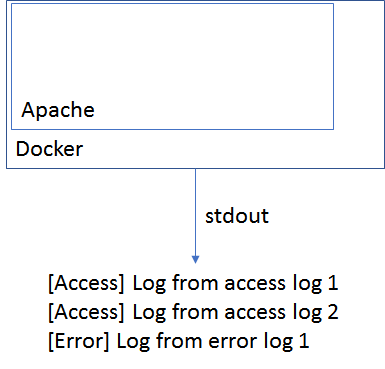
How can we achieve this? Well there are two options:
- Change the log format and apply your log tag directly here
- Write a log file in your container, tail -F that file, and echo your tag before outputting it to the stdout stream
It can also be thought about adding the type of the container like Apache as an additional tag like [Apache] [Access] Log message from access log.