In the previous part of this two-part article series, I introduced all ingredients that are necessary to create a reputation mechanism for distributed oracle networks. We will directly continue on our journey on how to make the data supply for smart contracts a bit more secure.
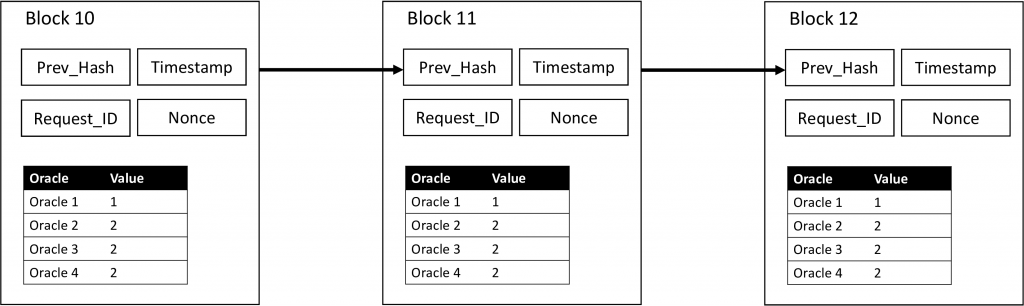
The main contribution of my Master’s thesis was the identification of possible formulas that we could use to calculate the reputation of an oracle node within a distributed oracle network. By using a Blockchain and saving oracle answers to that irreversible data structure, we get a history about all answers that an oracle node gave in the past (see Figure 1). It is possible to use that history, to calculate a reputation score for a specific oracle node and thus eventually predict the future behaviour and detect malicious nodes.
The main research questions of my thesis were:
- What existing reputation mechanisms / formulas could be used for distributed oracle networks
- What possible reputation dimensions / parameters could be used in that scenario? (Latency, speed,…)
- What specific attack scenarios exist for a Blockchain based distributed oracle network based on existing attack scenarios for normal P2P reputation mechanisms.
References
Reputation mechanisms have a long history in P2P systems. I did a lot of research and identified three basis mechanisms:
- Beta Reputation System: Audun Jøsang and Roslan Ismail. The beta reputation system.
- Bayesian Reputation System: Wang and J. Vassileva. Bayesian network-based trust model.
- Fuzzy Reputation System: Nathan Griffiths, Kuo Ming Chao, and Muhammad Younas. Fuzzy trust for peer-to-peer systems.
Maybe I will give a short introduction about these in future articles.
Parameters
The first step is to identify possible parameters / reputation dimensions for defining reputation in a distributed oracle network. Some examples will make it clearer what the term reputation dimensions or parameters mean:
- Time in the system (how long is a node already participating in the system)
- Last activity time (when was the last answer of a node?)
- Quality of the provided data (relative to other answers)
- Latency (relative to other answers)
- Data size (is the peer only serving small requests?)
The calculation of these parameters is straightforward:
- Time in the system: Current time – first answer time
- Last activity time: Current time – last answer time
- Quality: Relative distance of an answer compared to the other answers. Example
- Real answer: 20,
- Worst answer: 10,
- Answer: 15 -> distance 0.5 in the linear model
- Latency: Relative latency, starting from the first answer timestamp to the node’s answer timestamp
- Data size: Fixed reputation step sizes Bytes, KB, MB,…
Attack Scenarios
The general known attack scenarios for reputation systems in P2P networks are:
- Self-promotion: Giving yourself good ratings
- Traitor: First act honestly to build a high reputation and the using this to harm the network
- Whitewashing: Rejoin the network under a different identity to reset the reputation
- Slandering: Give a bad rating to other participants to harm their reputation
- DoS: Spam the network
- Orchestrated: Combination of multiple
Simulation
To test the three proposed formulas, I set up a simulation which consists of generated answers and blocks. The simulation included 100 blocks of the format as shown in Figure 2. The included parameters were already described earlier as well as the tested formulas. I defined different scenarios testing all single reputation dimensions (quality, time in the system, activity,..) and combined them later using some predefined weighting scheme.
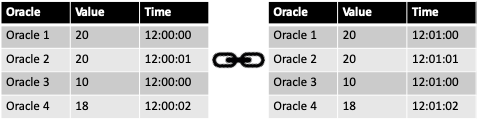
Examples
Three examples of the reputation at certain time-steps are the time in the system (Figure 3), the quality (Figure 4) and the combined traitor scenario (Figure 4) (a peer is first providing good quality and then decreasing the quality).
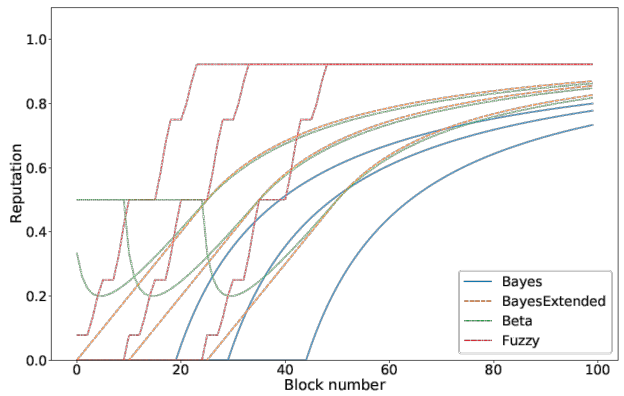
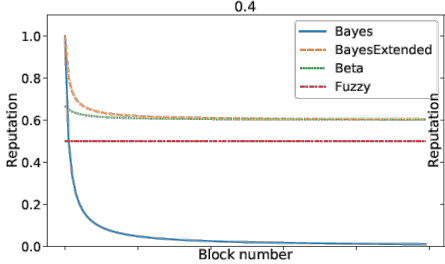
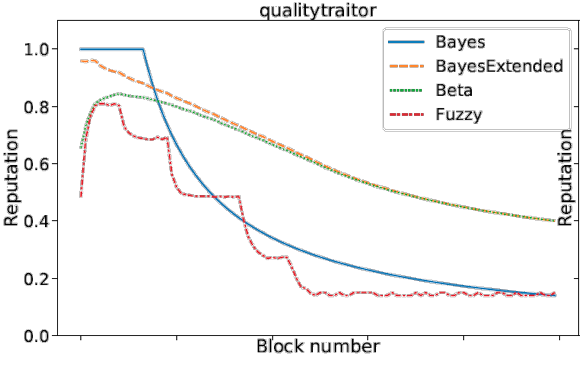
Conclusion
Honestly, my research is just the beginning of a long journey and a very small piece. I simulated three possible formulas to calculate the reputation of an oracle node based on its answer history derived from the Blockchain. So what conclusions can we make from the findings in my thesis?
- Reduction of the attack scenarios to a subset (because we use a blockchain)
- Self-promotion only from formula exploitation
- No collusion in the reputation distribution because the reputation is derived directly from the answer history
- Whitewasher attack is still possible but related to the formula
- Traitor attack is still possible
- 51 % attack for Blockchains to manipulate the answer history is possible
- Identification of various reputation dimensions
- Formulas are generally usable with some tweaks, the best result was made with an extended bayes version incorporating partial reputation
- Combination of parameters is necessary but how to weight?
I know this part was heavy, but if you are really interested, I would recommend to read my thesis. The final presentation is uploaded here:
Download the thesis: